5 zasad pisania w R dla każdego data scientista

Data scientist, który przechodzi z Excela na język R, styka się z wieloma problemami. Dlatego przygotowaliśmy pięć zasad pisania w R, które ułatwią przejście na ten język. Z poniższego artykułu dowiecie się m.in. dlaczego warto wyrzucić interaktywne programowanie do kosza, przestać pisać pętle oraz tego, dlaczego dokumentacja i organizacja kodu jest tak ważna.

Filip Cyprowski. Data Scientist w Yieldbird. Pasjonat data science, zarządzania i pisania w języku R (choć wie, że większość uważa R za nudny). W swojej pracy wykorzystuje też Pythona, zna SQL i wielbi Apache Sparka. Swoimi wieloma spostrzeżeniami dotyczącymi pracy data scientista dzieli się na blogu prowadzonym na LinkedInie.
Spis treści
1. Pracuj na czystym środowisku
Jest taka rzecz, która zdarza się szczególnie często wśród ludzi, którzy przeszli do R z Excela lub któregoś z jego klonów: coś im nie działa, a przecież działało wczoraj. W przypadku Excela masz dość prostą sytuację. Włączasz arkusz, a tam wszystko lata sobie tak jak zamierzałeś. W programowaniu jest inaczej, w programowaniu masz zmienne. Jeśli jakaś część skryptu jest zależna od zmiennej „x”, a ta została przez Ciebie zdefiniowana jako „kupa” dwanaście dni temu, kiedy wesoło sprawdzałeś działanie funkcji w konsoli, to skrypt zadziała, jakbyś do niego włożył kupę. Jaki z tego wniosek?
Czyść środowisko, najlepiej za każdym razem, kiedy odpalasz RStudio. Zaraz po tym, restartuj sesję (żeby odładować wszystkie pakiety), a potem jeszcze raz, kiedy uważasz, że skończyłeś pisać skrypt. Wyczyść środowisko i puść cały skrypt. Nie działa? „Couldn’t find function… blabla”? No właśnie. Czyść, restartuj i nie pisz całych kawałków kodu w konsoli. W ogóle najlepiej…
2. Wyrzuć interaktywne programowanie do kosza
Tutaj mamy dwa problemy. Po pierwsze, to kontrowersyjna teza, bo „R jest taki interaktywny, co jest takie fajne i w ogóle”. Po drugie, trzymanie się tej zasady może być trudne dla kogoś, kto zaczynał w Excelu, SPSS albo nawet SASie, gdzie wszystko jest interaktywne. Nie zrozum mnie źle, przy typowym, analitycznym wykorzystaniu R konsola potrafi być bardzo przydatna. Sam piszę pakiety, których używam wyłącznie w konsoli (np. do szybkiego sprawdzenia danych z ostatnich kilku dni). Ale jeśli chcesz, żeby R był czymś więcej dla twojej organizacji, niż tylko fancy excelem, to jak najszybciej z tego zrezygnuj.
R ma automatyzować przepływ danych, a nie być tylko kolejnym sposobem na klikanie po tabelkach. Im szybciej zaczniesz pisać skrypty, tym lepiej. A pisanie skryptów polega na ciągłym ich testowaniu w nieinteraktywnym środowisku (np. przez odpalanie ich komendą Rscript w bashu). Pamiętaj, że po to jest R – do wydobywania wiedzy z danych, bez konieczności każdorazowego przeklikiwania się po numerkach, wykresach itd.
3. Przestań pisać pętle
Dobra, przeszliśmy przez podstawy, teraz coś bardziej zaawansowanego. W społeczności R-owej krąży mit, że pętle „for” są generalnie niewydajne. I żeby zamiast nich używać rodziny funkcji „apply”. Ci co tak mówią mają rację… tylko, że NIE. Pętle są rzeczywiście szczególnie niewydajne, ale to samo tyczy się lapply, sapply i innych. Po prostu zapętlanie w R jest głupie, niepraktyczne i nie ma różnicy, czego do tego użyjemy, tak długo jak będzie to R (wyrażenie z for i lapply to w sensie technologicznym, wykorzystania pamięci, dokładnie to samo). Ale zaraz… R to język programowania, a programowanie to pętle i wyrażenia warunkowe!
No i prawda, tylko że większość pętli w R nie wymaga od nas pisania pętli. Jak to możliwe? Ano dzięki wektoryzacji. Jak myślisz, co dzieje się, kiedy mnożysz wektor? Przecież nadal wymaga to od ciebie wykonania operacji na każdym elemencie wektora. Tylko, że zamiast budować pętlę, napiszesz po prostu „wektor * 2”. Magia? Nie, po prostu pętla wykonuje się w C, na obiektach w C. Czyli po prostu szybszy język wykonuje pętlę na o wiele lżejszych obiektach. Odpada cały balast związany z metadanymi przypisanymi do obiektów R-owych. Zresztą cały koncept wektoryzacji sprawia, że R i inne języki z niego korzystające (jak pythonowe moduły numpy i dziedziczący po nim pandas) tak dobrze sprawdzają się przy przetwarzaniu danych. Po prostu pętle znajdują się na niższym poziomie kodu i są dobrze zoptymalizowane. Nie musimy ich pisać.
Oczywiście zdarza się, że operacja jest na tyle skomplikowana i niestandardowa, że napisanie pętli w R jest konieczne. Ale wiesz co? Zdarza się to bardzo rzadko. A dlaczego?
4. Programuj prosto, czyli „follow the tidy data tool manifesto”
Jeśli nie wiesz, kim jest Hadley Wickham to albo dopiero zaczynasz programować w R, albo przespałeś ostatnie kilka lat rozwoju tego języka. Krotko mówiąc jest to koleś, który stworzył współczesnego Ra i prawdziwy zbawiciel, dzięki któremu nawet przy naprawdę skomplikowanych zadaniach nie musimy pisać tych cholernych pętli. Więc – już kończę ten temat – jeśli wydaje ci się, że nie możesz wykonać tego bardzo skomplikowanego zadania bez dwóch zagnieżdżonych „forów”, to policz do dziesięciu, napij się kawy i pomyśl lepiej, co wpisać na StackOverflow.
Wróćmy do Hadleya. Swego czasu stworzył pakiet pakietów nazwany tidyverse, zawierający szereg funkcji, które ogarniają mniej lub bardziej skomplikowane operacje na data.frame’ach. Wiele z nich było już dostępnych wcześniej w bazowym R, ale zwykle były one niewygodne i słabo zoptymalizowane. Co więcej, korzystając z tidyverse jesteś w stanie zmieścić większość operacji w pipelinie (skrypcie przetwarzającym dane) w jednym ciągu operacji na pojedynczej tabeli. Trudno właściwie wyrazić słowami, jak bardzo ułatwia i upraszcza to programowanie w R. Praktycznie rezygnujesz z list, definiowanych przez ciebie klas i innych tego typu rzeczy. Jesteś tylko ty, podstawowe typy zmiennych (numeric, character itd.) i data.frame. I ciąg funkcji wykonujących zadania na stale zmieniającej się tabeli. Proste programowanie „input-output style” bez produktów ubocznych i obiektów z milionem atrybutów.
Oczywiście prawdziwie dobre programowanie zaczyna się, kiedy poznasz szereg zasad i zaczniesz je świadomie łamać. Ale jeśli chcesz poznać zasady programowania w R, to zacznij od tidy data tools manifesto.
5. Dokumentuj i organizuj
I ostatnia rzecz, największy wróg wolnych umysłów i młodych programistów w koszulkach ze śmiesznymi informatycznymi żarcikami – organizacja kodu. Po pierwsze, zamykaj logicznie spójne części kodu w pakiety. Masz szereg funkcji do wyciągania danych z Facebooka? Zamknij je w pakiecie, napisz dokumentację (polecam zobaczyć pakiet roxygen2) i skomentuj. Nazywaj też zmienne w taki sposób, że jak spojrzysz na kod za rok, będziesz w stanie mniej więcej powiedzieć, co ta zmienna zawiera. Podążaj za standardami kodowania w R (nie wszystkie są sensowne, ale większość tak). Śledź powtarzające się kawałki kodu i zamykaj je w funkcje.
Wiem, że brzmi to jak wykonywanie dodatkowej, zbędnej pracy (bo przecież „wszystko działa”), ale zaufaj mi, zbudowałem parę systemów do przetwarzania danych i wiem, ile zła wyrządza źle zorganizowany kod. Ile spędza się godzin na jego debugowaniu i ile razy przeklniesz, kiedy zobaczysz, że często wywoływana funkcja nazywa się „x4”.
Artykuł został pierwotnie opublikowany na blogu Filipa Cyprowskiego. Zdjęcie główne artykułu pochodzi z serwisu picjumbo.com.
Podobne artykuły

Python podstawy - kursy, tutoriale online - 10 rekomendacji

Data Analytics, Data Science, Machine Learning – co wybrać?

12 wniosków i dobrych praktyk z refaktoryzacji kodu

Nie jesteś przekonany do code review? Oto kilka porad na start
Jak Slack dba o każdego użytkownika? Stosuje accessible technology
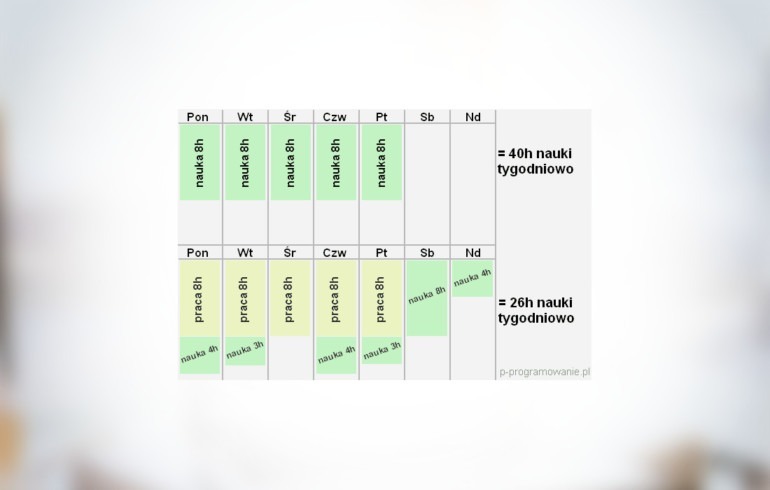
6 kroków do przebranżowienia się na programistę. Plan nauki IT

10 rad dla początkujących programistów od seniora
